統計の記号、斜体で書いていますか
この連載を読んで下さっている方は、おそらく日本語教育関係の方が多いと思います。そして、自分自身で卒業論文や研究論文を書いたり、他の方の論文を読んだりする機会が少なからずあるのではないでしょうか。その時にt検定と呼ばれる検定法の結果を見る機会もあると思いますが、次の例の①と②とではどちらの表現が正しいと思いますか。
① t (20)=1.883, p< .05
② t (20)=1.883, p< .05
また、相関係数と呼ばれる指標の大きさを表現するのに、
③ r = .65
④ r = .65
ではどちらの表現が正しいと思いますか。「どちらも正しいのでは?」と思う方もいらっしゃるかもしれませんが、統計的方法を使った研究の論文を読んだり書いたりした経験のある方々は「②と④が正しいのでは?」と思うかもしれません。学術雑誌では基本的に②と④の表現を用います。
上にあげたt、p、rだけではなく、 F(F値)、N(データ数)、df(自由度)、SD(標準偏差)、M(平均値)も斜体にするのが一般的です。日本語教育学会の学会誌『日本語教育』に掲載されている論文を見てみましたが、斜体になっていないものが多くありました。「t (20) =1.883, p< .05」「t (20) =1.883, p< .05」のように、一部のみ斜体になっている残念な例もあります。
なぜ統計の記号を斜体にするのか、今回調べてみましたが、納得のいく理由を見出すことはできませんでした。おそらく、英文で論文を書いた場合に、地の文と区別するためではないかと思います。そう考えると、日本語の場合は、必要性がないのかもしれませんね。念のため、過去に島田が書いた論文を確認したところ、「N」と書かれているのを発見しました。t、F、pは斜体になっていましたが…。しかし、一度刊行されたものは差し替えできませんので、くれぐれも気をつけましょう(自戒の念を込めて)。それにしても、いちいち斜体にするのは面倒な作業です。便利な変換ソフトはないものでしょうか。
*、†は参照マーク
表1は、4月の授業開始時と7月の授業終了時に自己評価アンケートを行い、4技能の得点をt検定で分析した結果です。表の一番右の列には、有意差があったかどうかを示す参照マークが書かれています。言語教育の論文では、一般的に、 5%水準で有意の時は「*」、 1%水準で有意の時は「**」で示します。参照マークが何を示すのかは表外に記します。
表1 自己評価の平均値
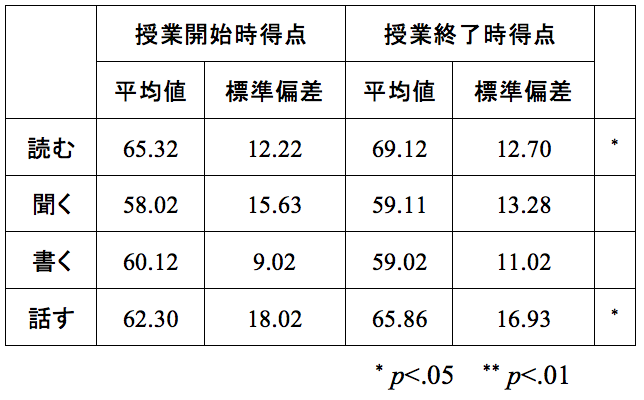
表1では、表の右下に「* p<.05 ** p<.01」と書かれています。つまり、「* が付されている箇所は5%水準で有意で、 ** が付されている箇所は1%水準で有意だ」ということを示しています。このことから、表中の「*」が記された「読む」と「話す」は 5%水準で有意差があることがわかります。では、1%水準はどれでしょう。表を見ても、「**」はどこにもありません。「*」や「**」は参照マークですから、表中にないものを表外に書くのはおかしいです。つまり、この場合は、「* p<.05」のみの記述でいいのです。ところが、この表のように、「p<.01」の結果がないのに「* p<.05 ** p<.01」と書いたり、有意傾向がないのに「†p<.1 * p<.05 ** p<.01」のように書いたり、まるで決まりごとのように記載する論文を時々見ますが、表中に使用した参照マークについてのみ説明するのが正しい書き方です。
また、参照マークである「*」はどこにもないのに、次のように記載されている例もありました。
t=0.761 p<.226 t=1.210 *p<.027 t=4.397 **p<.006
これはどう解釈したらいいのか難しいのですが、おそらく左(t=0.761 p<.226)は「t=0.761, p=.226」であり、すなわち「t=0.761, p>.10」ということを指していると思われます。真ん中(t=1.210 *p<.027)はおそらく「t=1.210, p=.027」であり、すなわち「t=1.210, p<.05」であると思われます。5%水準で有意なため「*」をつけているのではないでしょうか。右(t=4.397 **p<.006)も同様に「t=4.397, p<.01」という意味なので1%水準で有意と言いたいため「**」をつけたのでしょう。この誤りの原因は、「*」が参照マークだと言うことを理解しておらず、「* p<.05 ** p<.01」と書かれているのを他の論文で見て、「5%水準で有意の場合は「p」の前に「*」、1%水準で有意の場合は「p」の前に「**」をつける」そして「「p」と有意確率の間には「<」を書く」と機械的に思い込んだため起きたとしか考えられません。
この例では、不等号(<、>)の使い方も間違えていました。なぜ不等号を使用するのでしょう。それは、設定した有意水準(たとえば、1%水準)より大きい値なのか小さい値なのかを示すことが重要だからです。ですから、不等号の右に来る数値は有意水準になるべきなのです。
また、図1のように、t検定の結果を図で示し、非母語話者と母語話者との間で平均値に有意差のあった項目番号に「*」をつけている例を見かけます。先述したように、おおむね「*」は5%水準、「**」は1%水準で有意差があることを示します。しかし、「*」は、あくまでも参照マークですから、表外に「* p<.05 ** p<.01」と記載しなくてはいけません。この記載がない例は多く見られます。また、「4番*」のように上付けで記述するのが正しいです。ちなみに、この図は、この連載の第1回でも指摘しましたが、平均値を表すものとしては望ましくありません。
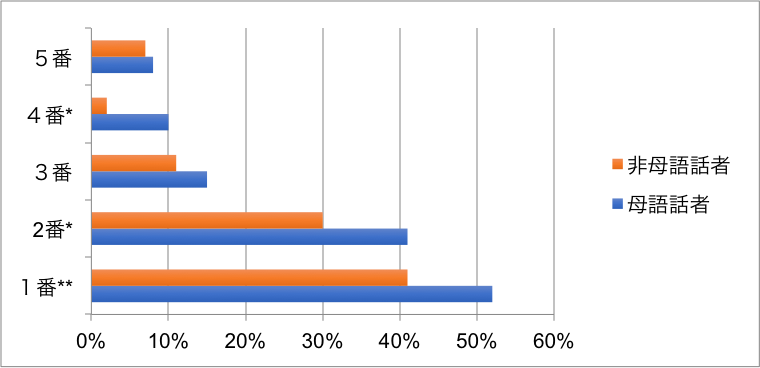
図1 t検定結果例
繰り返しますが、「*」は参照マークです。論文中で注のマークを入れたら、ページの下部か本文の最後に注について説明を書きますが、それと同じです。参照される「*」がないのに「*」の説明をするのもおかしいですし、「*」があるのに参照する「*」の説明がないのもおかしいです。安易に先行研究を模倣するのではなく、なぜ参照マークを使用するのか、なぜ不等号を使用するのか、その意味を理解していれば、これまであげた誤りは避けられるはずです。
記号は正しく
さて、「有意傾向」を示す時は、「*」ではなく「†」を参照マークとして使用するのが一般的です。ところが、「+」と書いている論文が多々あります。「+」を参照マークとすることも可能かもしれませんが、「†」の入力方法がわからず「+」と入力したか、参考にした先行研究に「+」と書いてあったのかもしれません。「†」は「ダガー(dagger)」と読み、短剣(ダガーナイフ)を意味しています。「ダガー」と入力して変換すれば「†」は入力できます。
ところで、「†」の入力のしかたがわからなかったかたも多いと思いますが、そのほか、「χ」(カイ)を「x」(エックス)と書く人がいます。「χ」と「x」の違いがこのページでは明確ではないかもしれませんので、下にカイの画像をはりつけます。
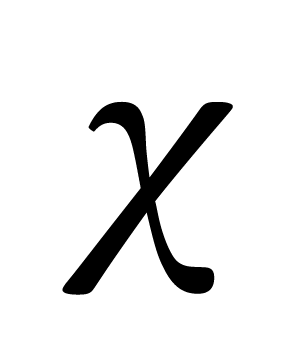
ここで使うカイはギリシャ文字の小文字です。「カイ」の文字を入力したいときは「カイ」と入力し変換すれば候補にあがってきます。本連載では、「カイ」が「x」(エックス)に見えるといけないので、「カイ二乗検定」と記載します。ちなみに「カイ二乗検定」ですから、「χ」に続く「2」は、![]() のように、上付きにする必要があります。もちろん半角です。くれぐれも「x2」(エックス2)とはしないでください。
のように、上付きにする必要があります。もちろん半角です。くれぐれも「x2」(エックス2)とはしないでください。
参照マークの「*」も時折「*」と書かれているのを見ることがありますが、通常は半角で上付きにします。
小数点の桁数
表2は、表1とほぼ同じ表で、4月の授業開始時と7月の授業終了時に自己評価アンケートを行い、4技能の得点をt検定で分析した結果を表しています。数値を見て、気になる箇所はないでしょうか。
表2 自己評価の平均値
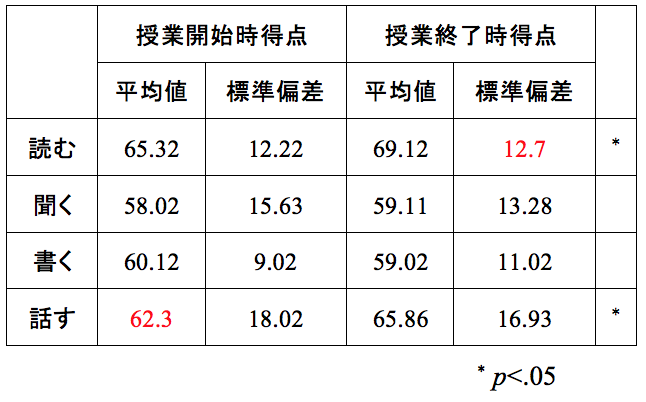
赤で記した数値を見てください。「授業開始時の「話す」の平均値」と「授業終了時の「読む」の標準偏差」のみ小数点以下第一位までしか記載がありませんが、ほかはすべて第二位まで記載されています。このように書かれている理由は、入力ミスの可能性もありますが、学生の例を見るとExcelが原因の場合があるようです。Excelは初期設定で、小数点最後の「0」は省略されることになっているようで、「2.0」と入力しても「2」と表示されます。しかし、必ず小数点はそろえて書くべきです。Excelで「0」が省略されている場合は、小数点の設定を変えれば表示できますし、Wordにコピーしてから「0」を加筆してもいいと思います。
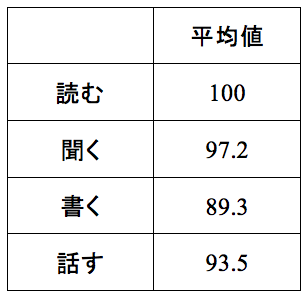
表3も小数点が揃っていない例です。「読む」の平均値が「100」になっていますが、これも「100.0」とするべきです。「100」だけでは、「99.7」という可能性もあるので、「100.0」と示します。
表3 テスト得点の平均値
統計ソフトの出力のまま表としない
SPSSなどの統計ソフトを使用すると、簡単に検定の結果が出力されます。大学院の授業や修士論文でよく見るのが、統計ソフトで出力された表をそのまま使用する例です。出力された表には、論文で報告する必要のない値も含まれています。
例えば次の図2は統計ソフトSPSSでt検定を行ったときに出力されたサンプルです。図2のように、統計量(図2では「グループ統計量」)と検定結果(図2では「独立サンプルの検定」)が表示されます。t検定の結果は、「独立サンプルの検定」に出力されています。「独立サンプルの検定」を見ると、t検定の結果は2段にわけて、2種類表示されています。等分散が仮定された場合は上段、仮定されない場合は下段の結果を使用しますので、どちらかは不要な情報となります。
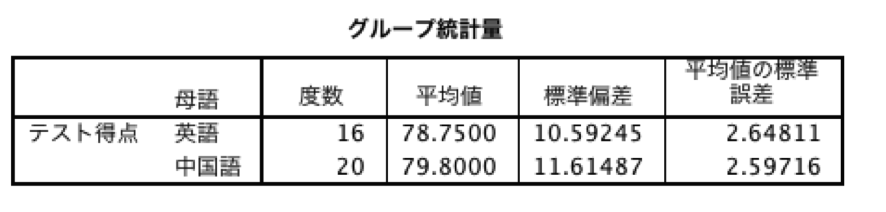

図2 SPSS出力例
通常、t検定を実施した結果を論文などに載せる場合には、平均値、標準偏差のほか、自由度、t値、有意確率を報告しますので、それ以外の、「グループ統計量」に記載されている平均値の標準誤差、「独立サンプルの検定」に記載されている平均値の差、差の標準誤差、差の95%信頼区画は必要ありません。不要な情報を削除して、表を作り直す必要があります。たとえば、この場合は表4のようになります。表5のようにt検定の結果を表に入れ込むこともあるかもしれませんが、文章中に「t(34)=-.280, p>.10」のように書き込むことのほうが多いです。また、小数点以下の桁数を見ると、例えば平均値が図2では4桁であるのに対して、表4では1桁になっています。SPSSは小数点以下の桁数が図2のように大変多く表示されますが、報告する時はそこまでの桁数にする必要はありません。1点刻みのテスト得点の平均値で、たとえば「72.24」と「72.25」の違いには意味がないことは言うまでもないでしょう。表4と表5では1桁で表示しましたが、より詳しい精度が必要な場合には2桁で表すこともあります。必要な桁数に整理した方が数値も見やすくなります。桁数をどのぐらいにするかは、その桁数がどの程度意味をなすかを考えて判断します。面倒でも、必要不可欠な情報は残し、不要な情報は削除して、わかりやすい表作成を心がけましょう。
表4 作表の例
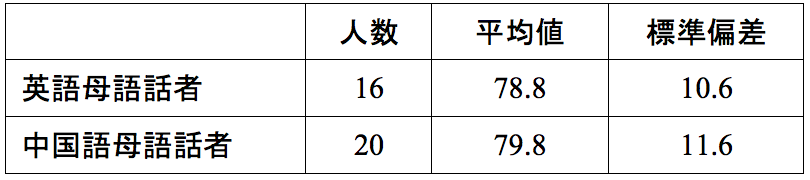
表5 作表の例(検定結果を含める)

まとめ
今回は結果を報告する際の記述方法に関する誤りを取り上げました。まとめると次のようになります。
- 統計の記号は斜体で記載します。
- 「*」などの参照マークを使用したら、その意味を記載します。そして、使っていない参照マークについては、解説は不要です。
- 参照マークや統計の記号は正しく書きましょう。特に間違いが多いのは、「†」(ダガー)や「χ」(カイ)です。
- 小数点以下の桁数を揃えます。「0」も省略せず書きます。
- 統計ソフトで出力された表はそのまま使わず、必要なデータを取捨選択して報告します。
統計は、計算したら終わりではなく、正しく報告するところまでが大事な過程です。今回あげた例は瑣末なことのように思われるかもしれませんが、そうではありません。適切に報告しないとせっかくの結果を正しく伝えることができなくなってしまいますので、最後まで気を抜かず記述を完成させましょう。


